不同的人对流畅性(卡顿掉帧)有不同的理解,对卡顿阈值也有不同的感知,所以有必要在开始这个系列文章之前,先把涉及到的内容说清楚,防止出现不同的理解,也方便大家带着问题去看这几篇问题,下面是一些基本的说明
- 对手机用户来说,卡顿包含了很多场景,比如在 滑动列表的时候掉帧、应用启动白屏过长、点击电源键亮屏慢、界面操作没有反应然后闪退、点击图标没有响应、窗口动画不连贯、滑动不跟手、重启手机进入桌面卡顿 等场景,这些场景跟我们开发人员所理解的卡顿还有点不一样,开发人员会更加细分去分析这些问题,这是开发人员和用户之间的一个认知差异,这一点在处理用户(或者测试人员)的问题反馈的时候尤其需要注意
- 对开发人员来说,上面的场景包括了 流畅度(滑动列表的时候掉帧、窗口动画不连贯、重启手机进入桌面卡顿)、响应速度(应用启动白屏过长、点击电源键亮屏慢、滑动不跟手)、稳定性(界面操作没有反应然后闪退、点击图标没有响应)这三个大的分类。之所以这么分类,是因为每一种分类都有不太一样的分析方法和步骤,快速分辨问题是属于哪一类很重要
- 在技术上来说,流畅度、响应速度、稳定性(ANR)这三类之所以用户感知都是卡顿,是因为这三类问题产生的原理是一致的,都是由于主线程的 Message 在执行任务的时候超时,根据不同的超时阈值来进行划分而已,所以要理解这些问题,需要对系统的一些基本的运行机制有一定的了解,本文会介绍一些基本的运行机制
- 流畅性这个系列主要是分析流畅度相关的问题,响应速度和稳定性会有专门的文章介绍,在理解了流畅性相关的内容之后,再去分析响应速度和稳定性问题会事半功倍
- 流畅性这个系列主要是讲如何使用 Systrace (Perfetto) 工具去分析,之所以 Systrace 为切入点,是因为影响流畅度的因素很多,有 App 自身的原因、也有系统的原因。而 Systrace(Perfetto) 工具可以从一个整机运行的角度来展示问题发生的过程,方便我们去初步定位问题
了解卡顿原理
卡顿现象及影响
如文章开头所述,本文主要是分析流畅度相关的问题。流畅度是一个定义,我们评价一个场景的流畅度的时候,往往会使用 fps 来表示。比如 60 fps,意思是每秒画面更新 60 次;120 fps,意思是每秒画面更新 120 次。如果 120 fps 的情况下,每秒画面只更新了 110 次(连续动画的过程),这种情况我们就称之为掉帧,其表现就是卡顿,fps 对应的也从 120 降低到了 110 ,这些都可以被精确地监控到
同时掉帧帧的原因非常多,有 APP 本身的问题,有系统原因导致卡顿的,也有硬件层的、整机卡的
用户在使用手机的过程中,卡顿是最容易被感受到的
- 偶尔出现的小卡顿会降低用户的使用体验,比如刷微博的时候卡了一下,比如返回桌面动画卡顿这种
- 整机出现卡顿的则会让手机无法使用
- 现在的高帧率时代,如果用户习惯了 120 fps ,在用户比较容易感知的场景下突然切换到 60 fps,用户也会有明显的感知,并觉得出现了卡顿
所以不管是应用还是系统,都应该尽量避免出现卡顿,发现的卡顿问题最好优先进行解决
卡顿定义
我对卡顿的定义是:**稳定帧率输出的画面出现一帧或者多帧没有绘制 。**对应的应用单词是 Smooth VS Jank
比如下图中,App 主线程有在正常绘制的时候(通常是做动画或者列表滑动),有一帧没有绘制,那么我们认为这一帧有可能会导致卡顿(这里说的是有可能,由于 Triple Buffer 的存在,这里也有可能不掉帧)
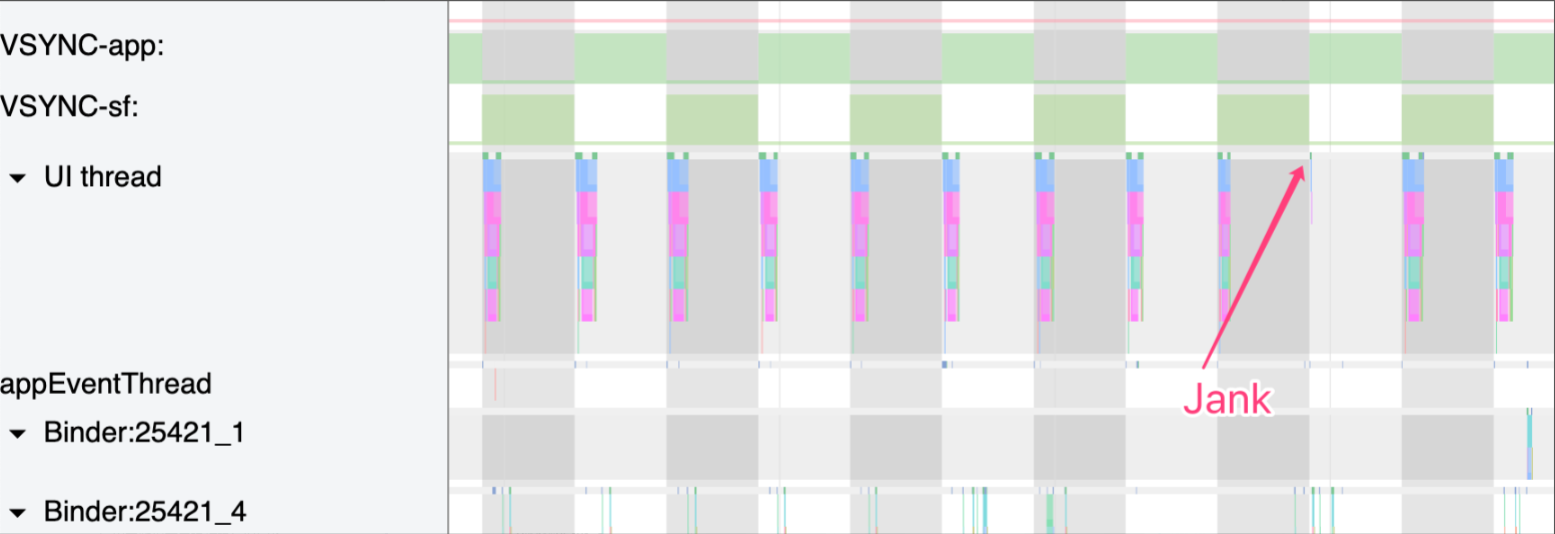
下面从三个方面定义卡顿
- 从现象上来说,在 App 连续的动画播放或者手指滑动列表时(关键是连续),如果连续 2 帧或者 2 帧以上,应用的画面都没有变化,那么我们认为这里发生了卡顿
- 从 SurfaceFlinger 的角度来说,在 App 连续的动画播放或者手指滑动列表时(关键是连续),如果有一个 Vsync 到来的时候 ,App 没有可以用来合成的 Buffer,那么这个 Vsync 周期 SurfaceFlinger 就不会走合成的逻辑(或者是去合成其他的 Layer),那么这一帧就会显示 App 的上一帧的画面,我们认为这里发生了卡顿
- 从 App 的角度来看,如果渲染线程在一个 Vsync 周期内没有 queueBuffer 到 SurfaceFlinger 中 App 对应的 BufferQueue 中,那么我们认为这里发生了卡顿
这里没有提到应用主线程,是因为主线程耗时长一般会间接导致渲染线程出现延迟,加大渲染线程执行超时的风险,从而引起卡顿;而且应用导致的卡顿原因里面,大部分都是主线程耗时过长导致的
卡顿还要区分是不是逻辑卡顿,逻辑卡顿指的是一帧的渲染流程都是没有问题的,也有对应的 Buffer 给到 SurfaceFlinger 去合成,但是这个 App Buffer 的内容和上一帧 App Buffer 相同(或者基本相同,肉眼无法分辨),那么用户看来就是连续两帧显示了相同的内容。这里一般来说我们也认为是发生了卡顿(不过还要区分具体的情况);逻辑卡顿主要是应用自身的代码逻辑造成的
系统运行机制简介
由于卡顿的原因比较多,如果要分析卡顿问题,首先得对 Android 系统运行的机制有一定的了解,下面简单介绍一下分析卡顿问题需要了解的系统运行机制:
- App 主线程运行原理
- Message、Handler、MessageQueue、Looper 机制
- 屏幕刷新机制和 Vsync
- Choreogrepher 机制
- Buffer 流程和 TripleBuffer
- Input 流程
系统机制 - App 主线程运行原理
App 进程在创建的时候,Fork 完成后会调用 ActivityThread 的 main 方法,进行主线程的初始化工作
frameworks/base/core/java/android/app/ActivityThread.java
public static void main(String[] args) {
......
// 创建 Looper、Handler、MessageQueue
Looper.prepareMainLooper();
......
ActivityThread thread = new ActivityThread();
thread.attach(false, startSeq);
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
......
// 开始准备接收消息
Looper.loop();
}
// 准备主线程的 Looper
frameworks/base/core/java/android/os/Looper.java
public static void prepareMainLooper() {
prepare(false);
synchronized (Looper.class) {
if (sMainLooper != null) {
throw new IllegalStateException("The main Looper has already been prepared.");
}
sMainLooper = myLooper();
}
}
// prepare 方法中会创建一个 Looper 对象
frameworks/base/core/java/android/os/Looper.java
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
// Looper 对象创建的时候,同时创建一个 MessageQueue
frameworks/base/core/java/android/os/Looper.java
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread()
}
主线程初始化完成后,主线程就有了完整的 Looper、MessageQueue、Handler,此时 ActivityThread 的 Handler 就可以开始处理 Message,包括 Application、Activity、ContentProvider、Service、Broadcast 等组件的生命周期函数,都会以 Message 的形式,在主线程按照顺序处理,这就是 App 主线程的初始化和运行原理,部分处理的 Message 如下
frameworks/base/core/java/android/app/ActivityThread.java
class H extends Handler {
public static final int BIND_APPLICATION = 110;
public static final int EXIT_APPLICATION = 111;
public static final int RECEIVER = 113;
public static final int CREATE_SERVICE = 114;
public static final int SERVICE_ARGS = 115;
public static final int STOP_SERVICE = 116;
public void handleMessage(Message msg) {
switch (msg.what) {
case BIND_APPLICATION:
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "bindApplication");
AppBindData data = (AppBindData)msg.obj;
handleBindApplication(data);
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
break;
}
}
}
系统机制 - Message 机制
上一节应用的主线程初始化完成后,主线程就进入阻塞状态,等待 Message,一旦有 Message 发过来,主线程就会被唤醒,处理 Message,处理完成之后,如果没有其他的 Message 需要处理,那么主线程就会进入休眠阻塞状态继续等待
从下图可以看到 ,Android Message 机制的核心就是四个:Handler、Looper、MessageQueue、Message
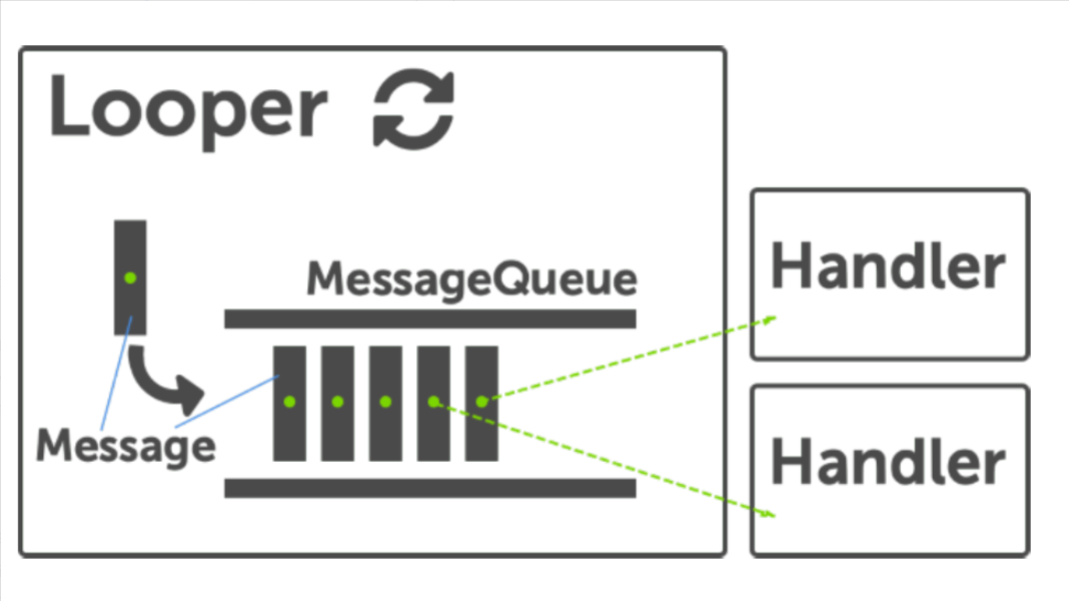
网上有很多关于 Message 机制代码细节的分析,所以这里只是简单介绍 Message 机制的四个核心组件的作用
- Handler : Handler 主要是用来处理 Message,应用可以在任何线程创建 Handler,只要在创建的时候指定对应的 Looper 即可,如果不指定,默认是在当前 Thread 对应的 Looper
- Looper : Looper 可以看成是一个循环器,其 loop 方法开启后,不断地从 MessageQueue 中获取 Message,对 Message 进行 Delivery 和 Dispatch,最终发给对应的 Handler 去处理。由于 Looper 中应用可以在 Message 处理前后插入自己的 printer,所以很多 APM 工具都会使用这个作为性能监控的一个切入点,具体可以参考 Tencent-Matrix 和 BlockCanary
- MessageQueue:MessageQueue 入上图所示,就是一个 Message 管理器,队列中是 Message,在没有 Message 的时候,MessageQueue 借助 Linux 的 nativePoll 机制,阻塞等待,直到有 Message 进入队列
- Message:Message 是传递消息的对象,其内部包含了要传递的内容,最常用的包括 what、arg、callback 等
从 App 主线程运行原理可知,ActivityThread 的就是利用 Message 机制,处理 App 各个生命周期和组件各个生命周期的函数
系统机制 - 屏幕刷新机制 和 Vsync
首先我们需要知道什么是屏幕刷新率,简单来说,屏幕刷新率是一个硬件的概念,是说屏幕这个硬件刷新画面的频率:举例来说,60Hz 刷新率意思是:这个屏幕在 1 秒内,会刷新显示内容 60 次;那么对应的,90Hz 是说在 1 秒内刷新显示内容 90 次
与屏幕刷新率对应的,FPS 是一个软件的概念,与屏幕刷新率这个硬件概念要区分开,FPS 是由软件系统决定的 :FPS 是 Frame Per Second 的缩写,意思是每秒产生画面的个数。举例来说,60FPS 指的是每秒产生 60 个画面;90FPS 指的是每秒产生 90 个画面
VSync 是垂直同期( Vertical Synchronization )的简称。基本的思路是将你的 FPS 和显示器的刷新率同期起来。其目的是避免一种称之为”撕裂”的现象.
- 60 fps 的系统 , 1s 内需要生成 60 个可供显示的 Frame , 也就是说绘制一帧需要 16.67ms ( 1/60 ) , 才会不掉帧 ( FrameMiss ).
- 90 fps 的系统 , 1s 内生成 90 个可供显示的 Frame , 也就是说绘制一帧需要 11.11ms ( 1/90 ) , 才不会掉帧 ( FrameMiss ).
一般来说,屏幕刷新率是由屏幕控制的,FPS 则是由 Vsync 来控制的,在实际的使用场景里面,屏幕刷新率和 FPS 一般都是一一对应的
系统机制 - Choreographer
上一节讲到 Vsync 控制 FPS,其实 Vsync 是通过 Choreographer 来控制应用刷新的频率的
Choreographer 的引入,主要是配合 Vsync,给上层 App 的渲染提供一个稳定的 Message 处理的时机,也就是 Vsync 到来的时候 ,系统通过对 Vsync 信号周期的调整,来控制每一帧绘制操作的时机. 至于为什么 Vsync 周期选择是 16.6ms (60 fps) ,是因为目前大部分手机的屏幕都是 60Hz 的刷新率,也就是 16.6ms 刷新一次,系统为了配合屏幕的刷新频率,将 Vsync 的周期也设置为 16.6 ms,每隔 16.6 ms,Vsync 信号到来唤醒 Choreographer 来做 App 的绘制操作 ,如果每个 Vsync 周期应用都能渲染完成,那么应用的 fps 就是 60,给用户的感觉就是非常流畅,这就是引入 Choreographer 的主要作用
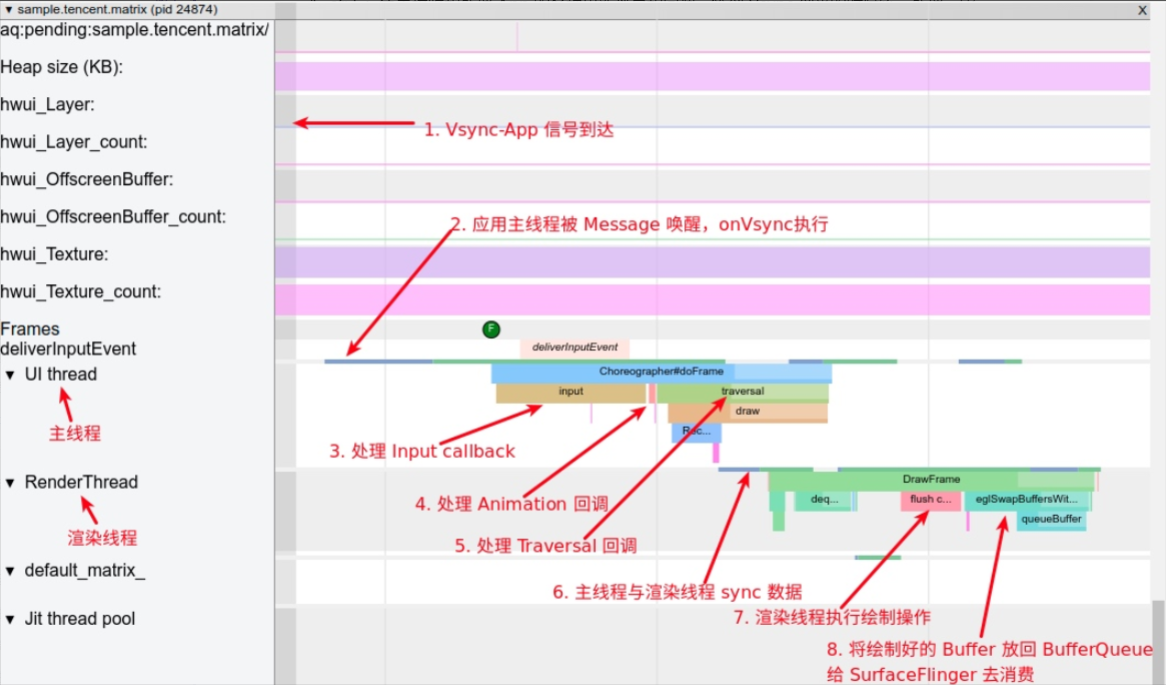
Choreographer 扮演 Android 渲染链路中承上启下的角色
- 承上:负责接收和处理 App 的各种更新消息和回调,等到 Vsync 到来的时候统一处理。比如集中处理 Input(主要是 Input 事件的处理) 、Animation(动画相关)、Traversal(包括 measure、layout、draw 等操作) ,判断卡顿掉帧情况,记录 CallBack 耗时等
- 启下:负责请求和接收 Vsync 信号。接收 Vsync 事件回调(通过 FrameDisplayEventReceiver.onVsync );请求 Vsync(FrameDisplayEventReceiver.scheduleVsync) .
下图就是 Vsync 信号到来的时候,Choreographer 借助 Message 机制开始一帧的绘制工作流程图
系统机制 - Buffer 流程和 TripleBuffer
BufferQueue 是一个生产者(Producer)-消费者(Consumer)模型中的数据结构,一般来说,消费者(Consumer) 创建 BufferQueue,而生产者(Producer) 一般不和 BufferQueue 在同一个进程里面
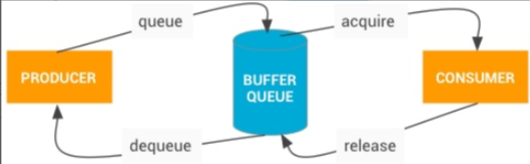
在 Android App 的渲染流程里面,App 就是个生产者(Producer) ,而 SurfaceFlinger 是一个消费者(Consumer),所以上面的流程就可以翻译为
- 当 App 需要 Buffer 时,它通过调用 dequeueBuffer()并指定 Buffer 的宽度,高度,像素格式和使用标志,从 BufferQueue 请求释放 Buffer
- App 可以用 cpu 进行渲染也可以调用用 gpu 来进行渲染,渲染完成后,通过调用 queueBuffer()将缓冲区返回到 App 对应的 BufferQueue(如果是 gpu 渲染的话,这里还有个 gpu 处理的过程,所以这个 Buffer 不会马上可用,需要等 GPU 渲染完成)
- SurfaceFlinger 在收到 Vsync 信号之后,开始准备合成,使用 acquireBuffer()获取 App 对应的 BufferQueue 中的 Buffer 并进行合成操作
- 合成结束后,SurfaceFlinger 将通过调用 releaseBuffer()将 Buffer 返回到 App 对应的 BufferQueue
知道了 Buffer 流转的过程,下面需要说明的是,在目前的大部分系统上,每个应用都有三个 Buffer 轮转使用,来减少由于 Buffer 在某个流程耗时过长导致应用无 Buffer 可用而出现卡顿情况
下图是双 Buffer 和 三 Buffer 的一个对比图
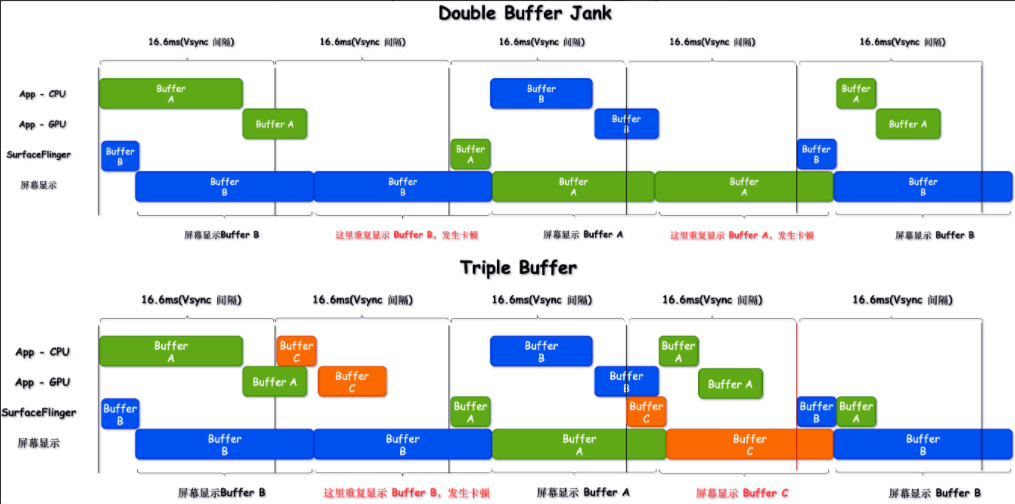
三 Buffer 的好处如下
- 缓解掉帧 :从上图 Double Buffer 和 Triple Buffer 的对比图可以看到,在这种情况下(出现连续主线程超时),三个 Buffer 的轮转有助于缓解掉帧出现的次数(从掉帧两次 -> 只掉帧一次)。,App 主线程超时不一定会导致掉帧,由于 Triple Buffer 的存在,部分 App 端的掉帧(主要是由于 GPU 导致),到 SurfaceFlinger 这里未必是掉帧,这是看 Systrace 的时候需要注意的一个点
- 减少主线程和渲染线程等待时间 :双 Buffer 的轮转,App 主线程有时候必须要等待 SurfaceFlinger(消费者)释放 Buffer 后,才能获取 Buffer 进行生产,这时候就有个问题,现在大部分手机 SurfaceFlinger 和 App 同时收到 Vsync 信号,如果出现 App 主线程等待 SurfaceFlinger(消费者)释放 Buffer,那么势必会让 App 主线程的执行时间延后
- 降低 GPU 和 SurfaceFlinger 瓶颈 :这个比较好理解,双 Buffer 的时候,App 生产的 Buffer 必须要及时拿去让 GPU 进行渲染,然后 SurfaceFlinger 才能进行合成,一旦 GPU 超时,就很容易出现 SurfaceFlinger 无法及时合成而导致掉帧;在三个 Buffer 轮转的时候,App 生产的 Buffer 可以及早进入 BufferQueue,让 GPU 去进行渲染(因为不需要等待,就算这里积累了 2 个 Buffer,下下一帧才去合成,这里也会提早进行,而不是在真正使用之前去匆忙让 GPU 去渲染),另外 SurfaceFlinger 本身的负载如果比较大,三个 Buffer 轮转也会有效降低 dequeueBuffer 的等待时间
坏处就是 Buffer 多了会占用内存
系统机制 - Input 流程
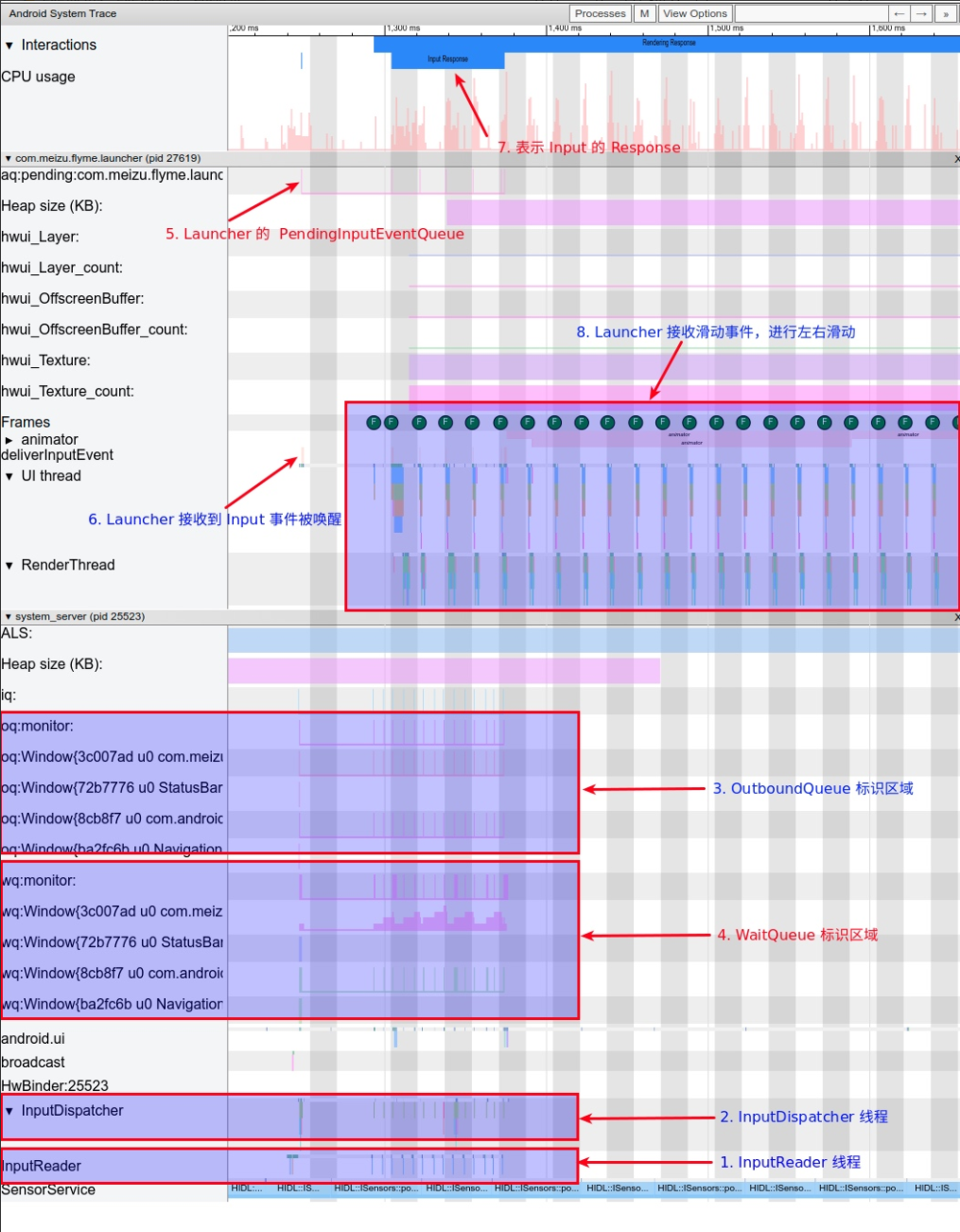
Android 系统是由事件驱动的,而 input 是最常见的事件之一,用户的点击、滑动、长按等操作,都属于 input 事件驱动,其中的核心就是 InputReader 和 InputDispatcher。InputReader 和 InputDispatcher 是跑在 SystemServer 里面的两个 Native 线程,负责读取和分发 Input 事件,我们分析 Systrace 的 Input 事件流,首先是找到这里。
- InputReader 负责从 EventHub 里面把 Input 事件读取出来,然后交给 InputDispatcher 进行事件分发
- InputDispatcher 在拿到 InputReader 获取的事件之后,对事件进行包装和分发 (也就是发给对应的)
- OutboundQueue 里面放的是即将要被派发给对应 AppConnection 的事件
- WaitQueue 里面记录的是已经派发给 AppConnection 但是 App 还在处理没有返回处理成功的事件
- PendingInputEventQueue 里面记录的是 App 需要处理的 Input 事件,这里可以看到已经到了应用进程
- deliverInputEvent 标识 App UI Thread 被 Input 事件唤醒
- InputResponse 标识 Input 事件区域,这里可以看到一个 Input_Down 事件 + 若干个 Input_Move 事件 + 一个 Input_Up 事件的处理阶段都被算到了这里
- App 响应 Input 事件 : 这里是滑动然后松手,也就是我们熟悉的桌面滑动的操作,桌面随着手指的滑动更新画面,松手后触发 Fling 继续滑动,从 Systrace 就可以看到整个事件的流程
上面流程对应的 Systrace 如下
adb 查看性能好坏
如果这个场景不卡,那么我们怎么衡量两台不同的机器在这个场景下的性能呢?
可以使用 adb shell dumpsys gfxinfo ,使用方法如下
- 首先确定要测试的包名,到 App 界面准备好操作
- 执行2-3次
adb shell dumpsys gfxinfo com.miui.home framestats reset,这一步的目的是清除历数据 - 开始操作(比如使用命令行左右滑动,或者自己用手指滑动)
- 操作结束后,执行
adb shell dumpsys gfxinfo com.miui.home framestats这时候会有一堆数据输出,我们只需要关注其中的一部分数据即可 - 重点关注
- Janky frames :超过 Vsync 周期的 Frame,不一定出现卡顿
- 95th percentile :95% 的值
- HISTOGRAM : 原始数值
- PROFILEDATA :每一帧的详细原始数据
我们拿这个场景,跟 Oppo Reno 5 来做对比,只取我们关注的一部分数据
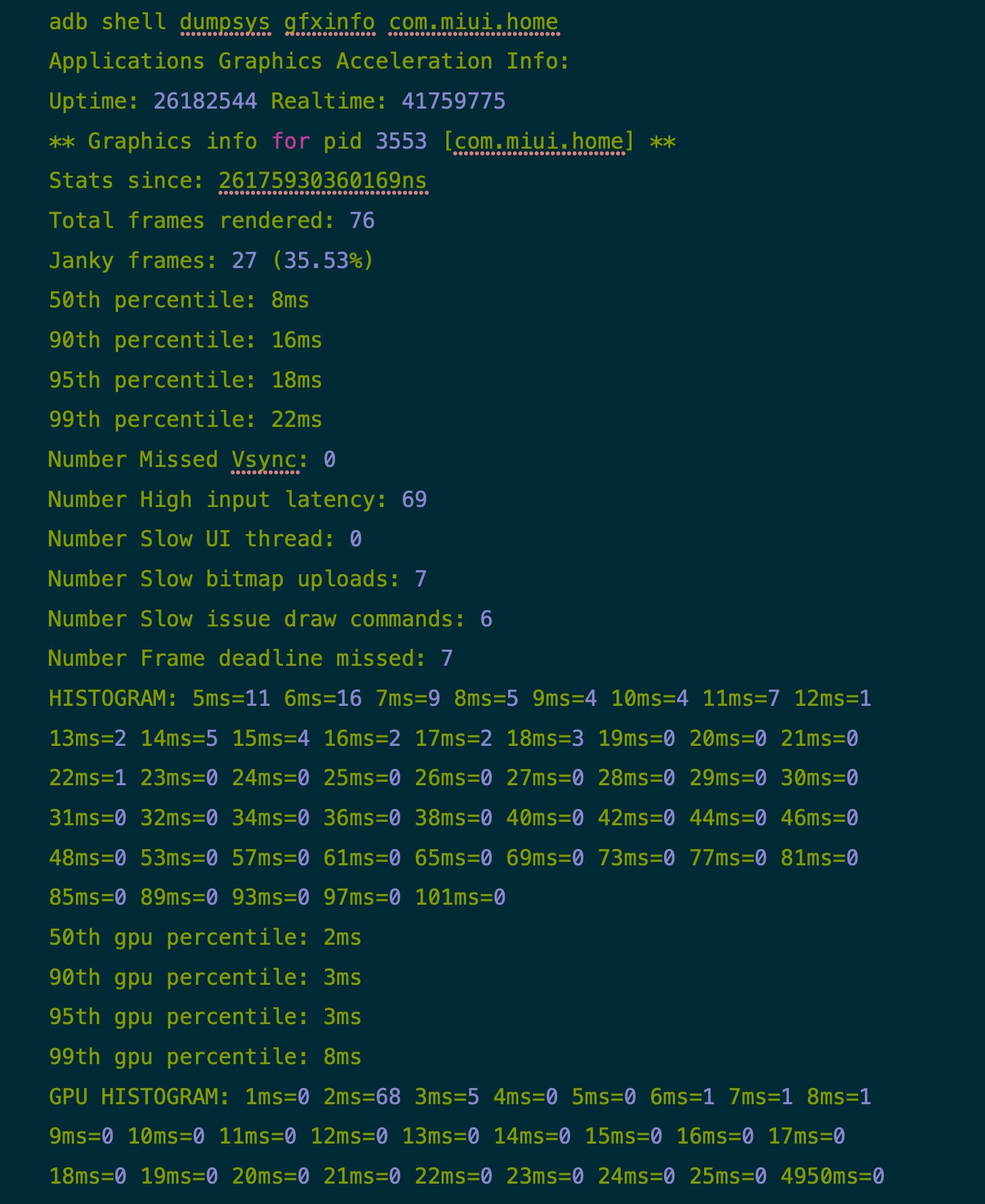
小米 - 90 fps
Oppo - 90 fps
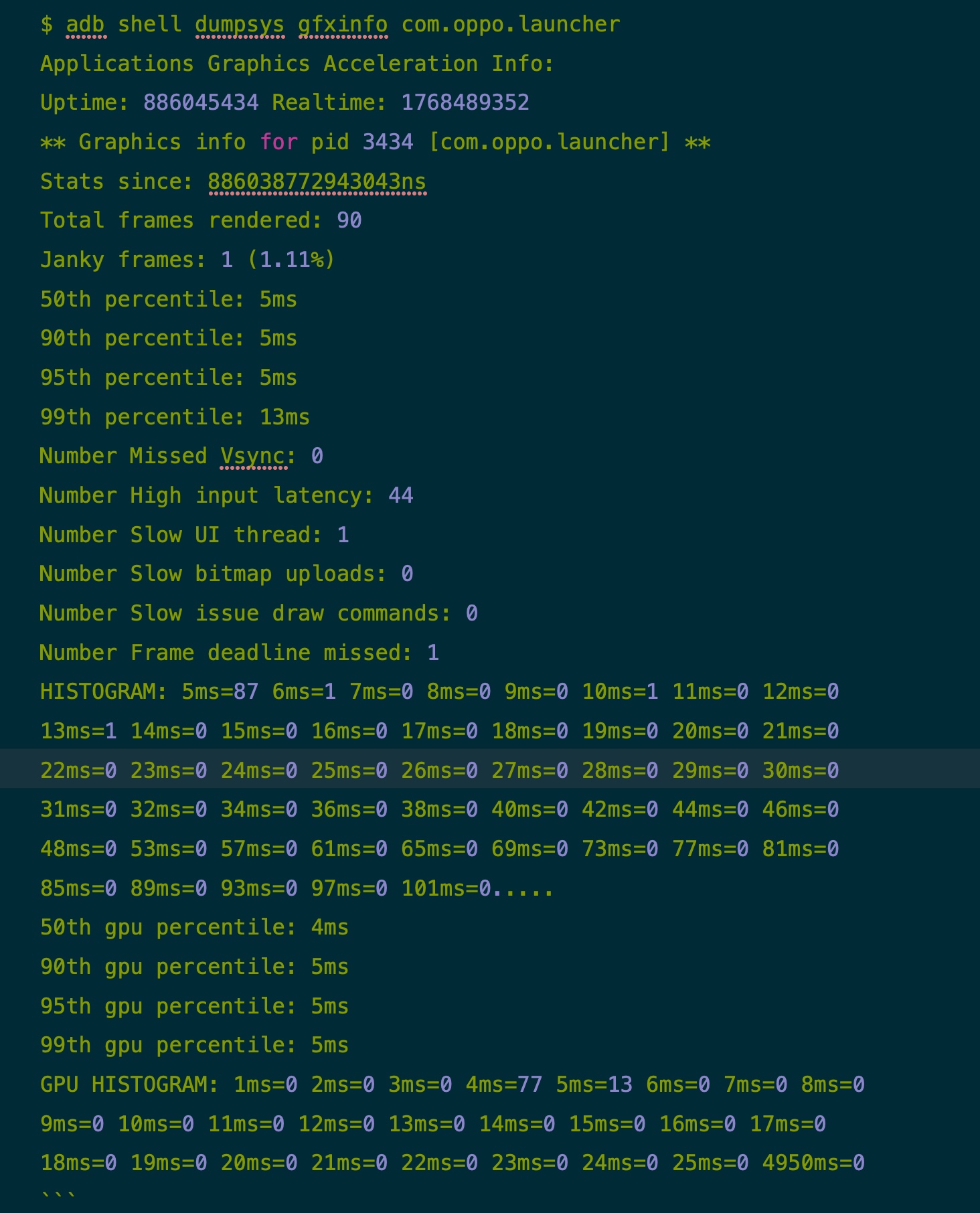
下面是一些对比,可以看到小米在桌面滑动这个场景,性能是要弱于 Oppo 的
- Janky frames
- 小米:27 (35.53%)
- Oppo:1 (1.11%)
- 95th percentile
- 小米:18ms
- Oppo:5ms
另外 GPU 的数据也比较有趣,小米的高通 865 配的 GPU 要比 Reno 5 Pro 配的 GPU 要强很多,所以 GPU 的数据小米要比 Reno 5 Pro 要好,也可以推断出这个场景的瓶颈在 CPU 而不是在 GPU
参考文章:
https://www.androidperformance.com/2021/04/24/android-systrace-smooth-in-action-1/