摘要
阿尔法元是Deepmind围棋软件AlphaGo的一个版本。AlphaGo团队于2017年10月19日在“ 自然 ” 杂志上发表了一篇文章,介绍了AlphaGo Zero,这个版本不用学习人类的游戏数据,比之前的版本更强大。AlphaGo Zero 在三天内通过自我对弈拥有了超过了AlphaGo Lee的实力,赢得100比0,在21天内达到了AlphaGo Master的水平,并在40天内超过了所有旧版本。它的学习从零开始,且单纯基于与自己的对弈。人类的输入没有超出游戏规则以外的任何指导、数据以及内部知识。本文探索一下AlphaGo Zero的算法工作原理、硬件、与AlphaGo对比。
关键词
AlphaGo Zero,算法,硬件,AlphaGo
1. 概要
Zero最明显的特点是:它的学习从零开始,且单纯基于与自己的对弈。AlphaGo是使用树搜索使用深度神经网络评估位置和选择移动。这些神经网络通过监督学习从人类专家的动作,并通过强化学习从自我发挥来训练。而zero完全基于强化学习的算法,没有人工数据、指导或超出游戏规则的领域知识。
AlphaZero无需任何人类专家策略作为输入内容,这样的能力无论如何夸大都不为过。这意味着AlphaGo Zero的底层方法能够利用完美信息(即比赛双方皆可随时了解全盘信息)适应任何游戏,即除游戏规则之外不再需要任何预先提供的专业指导。
也正因为如此,DeepMind才能够在初始AlphaGo Zero论文发布的短短48天之后,发布国际象棋与将棋版本。毫不夸张地讲,我们需要做的仅仅是变换用于描述游戏机制的输入文件,同时调整与神经网络以及蒙特卡洛树搜索相关的超参数。
2. 对比
AlphaGo Zero在几个重要方面不同于AlphaGo Fan和AlphaGo Lee12。首先,也是最重要的,它是完全通过自我游戏强化学习进行训练,从随机游戏开始,没有任何监督或使用人类数据。其次,它只使用棋盘上的黑白棋子作为输入特征。第三,它使用单一的神经网络,而不是单独的策略和价值网络。最后,它使用了一个更简单的树搜索,它依赖于这个单一的神经网络来评估位置和样本移动,而不执行任何蒙特卡罗滚动。为了实现这些结果,我们引入了一种新的强化学习算法,该算法在训练循环中加入了前向搜索,从而提高了学习的速度,提高了学习的精度和稳定性。进一步的技术差异,在搜索算法,培训程序和网络架构中描述的方法。
3. 算法
先看一下概况:
1. 通过潜在的未来场景设计游戏思维,优先考虑更具前景的途径,同时考虑对方可能选择的反应行为,同时继续探索未知。
2. 在达成某种陌生状态后,评估对当前优势位置的信心,并将评分与此前采取的达成当前状态的思维途径进行映射。
3. 在完成对未来可能性的思考之后,采取探索程度最高的行动。
4. 在游戏结束时,返回并评估一切错误的未来位置价值评估,并相应更新自身理解。
算法采用自对弈强化学习,不再需要学习人类棋谱数据。
模型由原来的两个模型变成只使用一个神经网络。
先将围棋问题转化为强化学习过程:
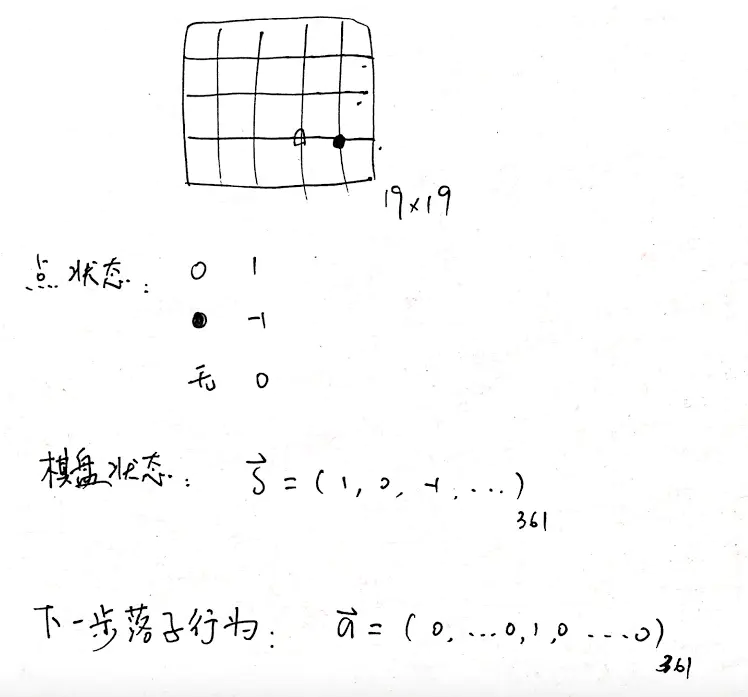
一个棋盘上有 19×19=361 个交叉点可以落子。
每个点有三种状态,白,黑,无子,分别用 1,-1,0表示。
这样一个棋盘的状态是一个长为 361 的向量 S。
下一步的落子行动用 a 表示,也是长为 361 的向量,例如第几个位置为 1 就表示在棋盘上换算后相应的第几行第几列下白子。
这样围棋问题就转化为:任意给定一个状态 S,寻找最优的应对策略 a,使得能够获得棋盘上的最大地盘。
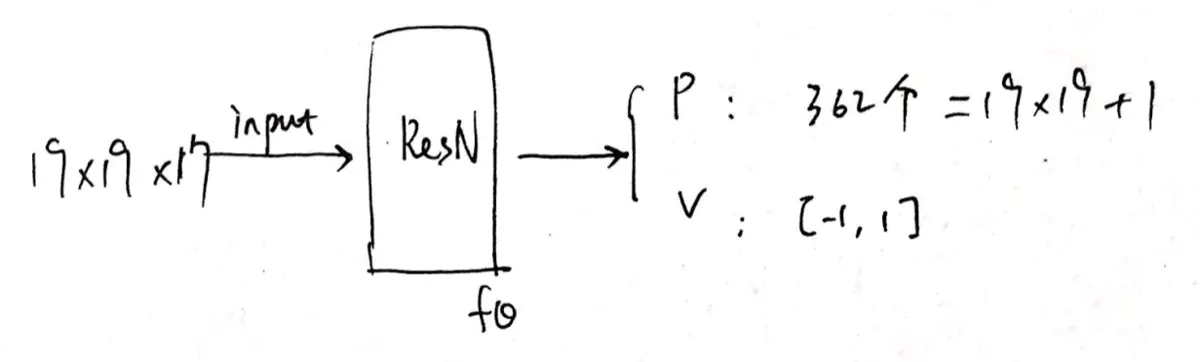
是基于 ResNet 的卷积网络,包含 20 或 40 个 Residual Block,加入批量归一化和非线性整流器模块。
输入为 19×19×17 的 0/1 值:包括17个二元特征平面的图像堆栈。
(The input to the neural network is a 19 × 19 × 17 image stack comprising 17 binary feature planes.)
输出为 落子概率 p 和一个评估值 v。P 即下一步在每一个可能位置落子的概率,v 表示当前选手在输入的历史局面下的胜率。
(A fully connected linear layer that outputs a vector of size 19×19 + 1 = 362, corresponding to logit probabilities for all intersections and the pass move)
自对弈强化学习算法:
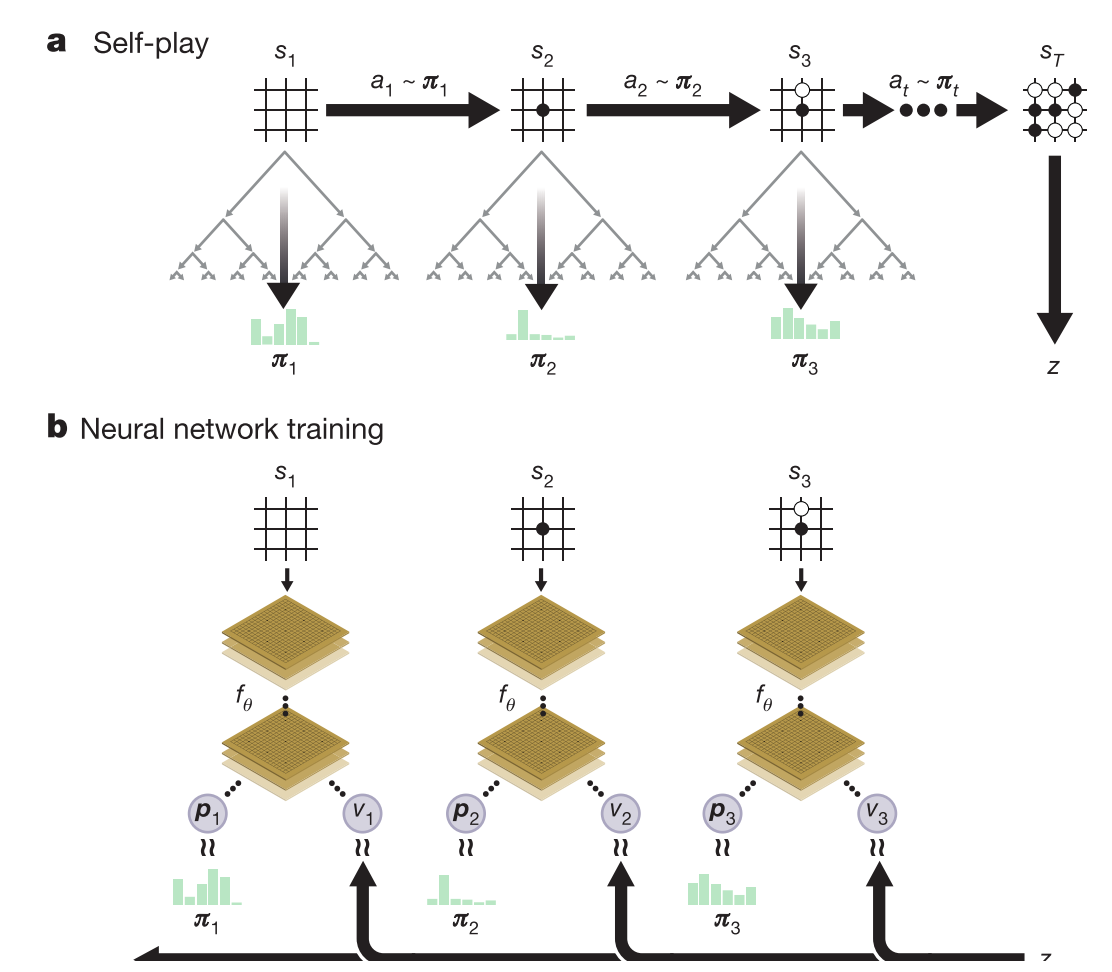
在每一个状态 S,利用深度神经网络 fθ 的输出作为参照执行 MCTS 蒙特卡洛搜索树算法,MCTS 搜索的输出是每一个状态下在不同位置对应的概率 π。
上图 a 表示自对弈过程 s1,…,sT。在每一个位置 st,使用最新的神经网络 fθ 执行一次 MCTS,根据得出的概率 at∼πi 落子,终局计算出胜者 z。
上图 b 表示神经网络 fθ 的参数更新过程。st 作为输入,得到下一步所有可能落子位置的概率分布 pt 和当前状态下选手的赢棋评估值 vt。
更新参数 θ 时,以最大化 pt 与 πt 的相似度和最小化预测的胜者 vt 和局终胜者 z 的误差为目标。
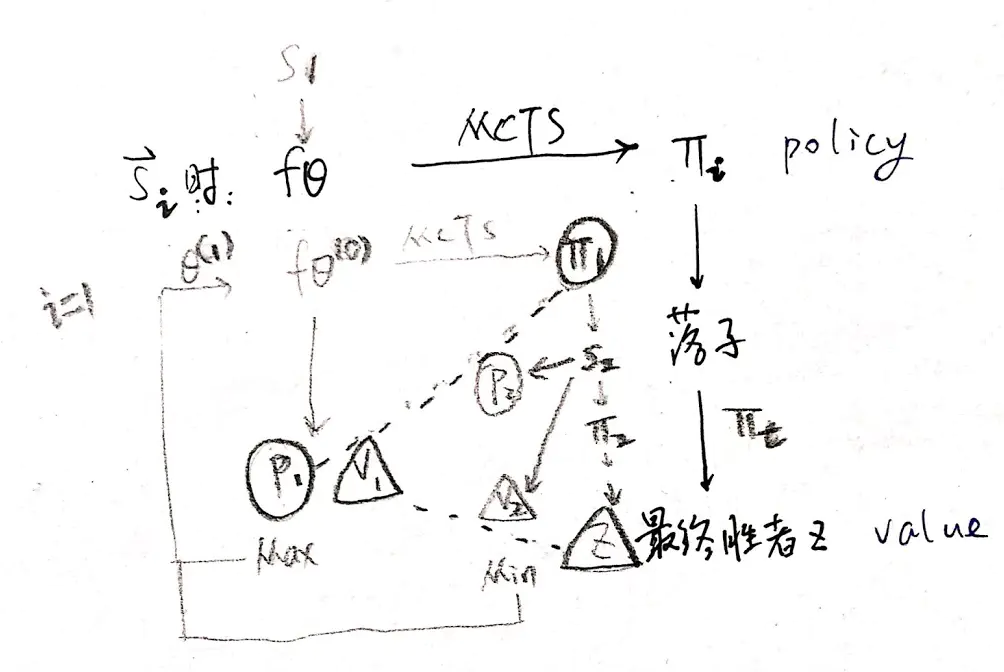
随机初始化 θ0
每一轮迭代 i⩾1,都自对弈一盘
第 t 步 MCTS 搜索 πt 进行落子
神经网络 fθ 以最大化 pt 与 πt 的相似度和最小化预测的胜者 vt 和局终胜者 z 的误差来更新参数 θ 。【1】
4. 硬件成本
一个AlphaGo Zero系统的硬件成本,包括定制组件,已经被报价为2500万美元左右。
|版本|硬件|Elo评分|比赛|
|:----:|---|---|---|
|AlphaGo Lee|48 TPUs, distributed|3,739|4:1 against Lee Sedol|
|AlphaGo Zero (40 days)|4 TPUs, single machine|5,185|100:0 against AlphaGo Lee;89:11 against AlphaGo Master|
5. 总结
结果全面证明了纯强化学习方法是完全可行的,即使在最具挑战性的领域:它是可能的训练到超人的水平,没有人类的例子或指导,没有知识的领域以外的基本规则。此外,与人类专家数据训练相比,纯强化学习方法只需要多几个小时的训练,并且实现了更好的渐近性能。通过这种方法,AlphaGo Zero击败了之前最强的版本,后者是通过手工特征从人类数据中训练出来的。人类从千百年来数以百万计的游戏中积累了围棋知识,这些游戏被浓缩成模式、谚语和书籍。在几天的时间里,AlphaGo Zero启动了白板程序,重新发现了很多围棋知识,以及为最古老的围棋提供新见解的新策略。
6. 引用
[1] https://www.jianshu.com/p/33b617239f41 AlphaGo Zero 的模型和算法